[1] 59.001 38.267 41.025 35.555 46.690 20.994 39.407 52.780 57.495 52.416
[11] 60.062 48.149 40.182 50.929 49.472 49.197 43.459 40.493 60.196 58.590
[21] 53.645 53.837 61.134 62.115 46.517 41.404 56.500 53.281 44.821 47.610
[31] 51.178 58.315 34.411 47.795 41.828 60.767 60.797 51.421 51.570 48.313
[41] 47.310 58.078 38.753 35.692 50.604 42.070 53.403 47.405 36.952 53.682DSC 3091- Advanced Statistics Applications I
Point Estimation and Confidence Intervals
Department of Statistics and Computer Science
Normal distribution - Maximum Likelihood Estimation
- The MLE of \(\mu\) is defined as \(\hat{\mu}_{MLE}=argmax(x_1,...,x_n|\mu,\sigma^2)\); where \(\hat{\mu}_{MLE}\) is the value of \(\mu\) that maximizes the likelihood function.

If we maximise the above likelihood function, we get \(\hat{\mu}_{MLE}=\bar{x}.\)
Since the MLE of \(\mu\) is the sample mean, computing the MLE in R becomes straightforward.
Confidence Interval for Mean
Case 1: When data is normal/ large sample and \(\sigma\) is known.
\[\bar{x}\pm z_{\alpha/2}\sigma/\sqrt{n}\]

Case 2: When data is normal/ large samples and \(\sigma\) is unknown.
\[\bar{x}\pm t_{n-1,\alpha/2}\sigma/\sqrt{n}\]

Case 3: When data is non-normal/ small samples
- For this, bootstrap approach is used as follows.

CONFIDENCE INTERVALS FOR Difference of Means
Case 1: Sampling from two independent normal distributions with known variances.

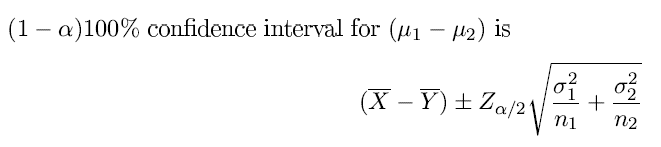
library("BSDA")
z.test(x,y = NULL,alternative = "two.sided",
sigma.x = NULL, sigma.y = NULL, conf.level = 0.95)Case 2: Sampling from two independent normal distributions with unknown variances (small samples).
- when population variances are equal

t.test(x,y,alternative = "two.sided",
var.equal=TRUE, conf.level = 0.95)- when population variances are unequal
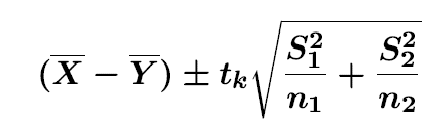
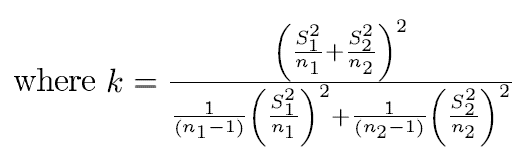
t.test(x,y,alternative = "two.sided",
var.equal=FALSE, conf.level = 0.95)Confidence Interval Chart in R (Independent Means & CIs)

- Example
set.seed(123456) # Create example data
data <- data.frame(x = c("A","B","C"),
y = round(runif(3, 10, 20),2),
lower = round(runif(3, 0, 10),2),
upper = round(runif(3, 20, 30),2))
library(ggplot2)
ggplot(data, aes(x, y)) + # ggplot2 plot with confidence intervals
geom_point() +
geom_errorbar(aes(ymin = lower, ymax = upper))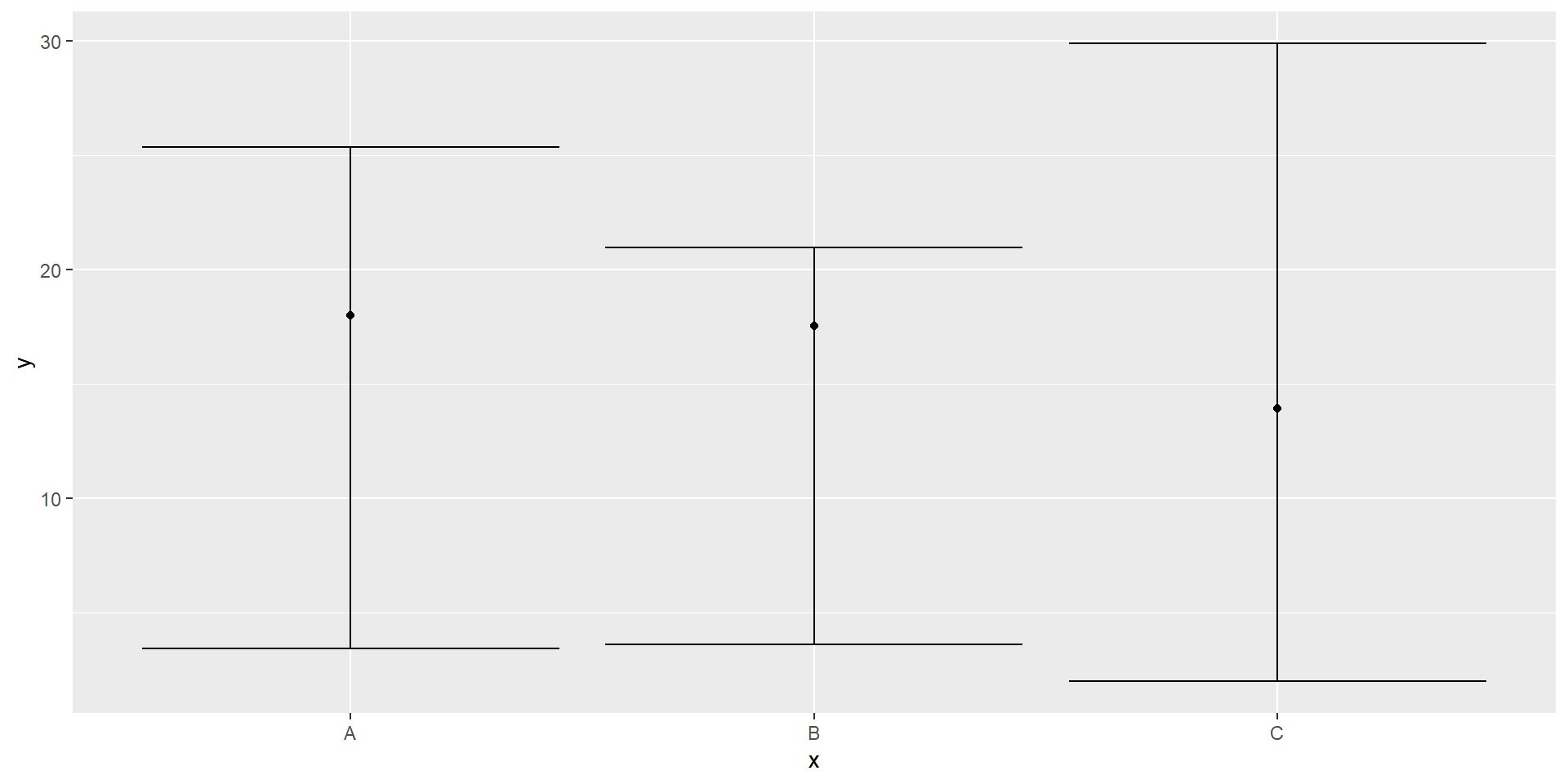
Confidence Intervals for Proportion
- Case 1: For large sample (Using Normal approximation)
\[ \hat{p}\pm Z_{\alpha/2}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\]

Case 1: For large sample (Using Binomial Distribution)
- we can use the following functions from R package epitools for this case.

Case 2: For small sample (Using Binomial Distribution)
- When sample size is small, confidence interval for population can be calculated using binom.test() function.
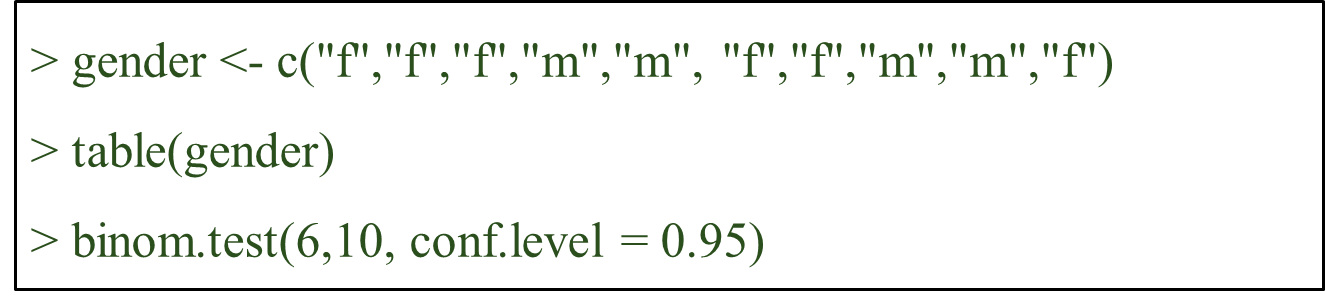
Case 2: Under non-normality assumption
- When no assumption is made about data, a bootstrap method is used to obtain confidence intervals for the population variance.
